15 min to read
Selecting the right database in Amazon Web Service(AWS)
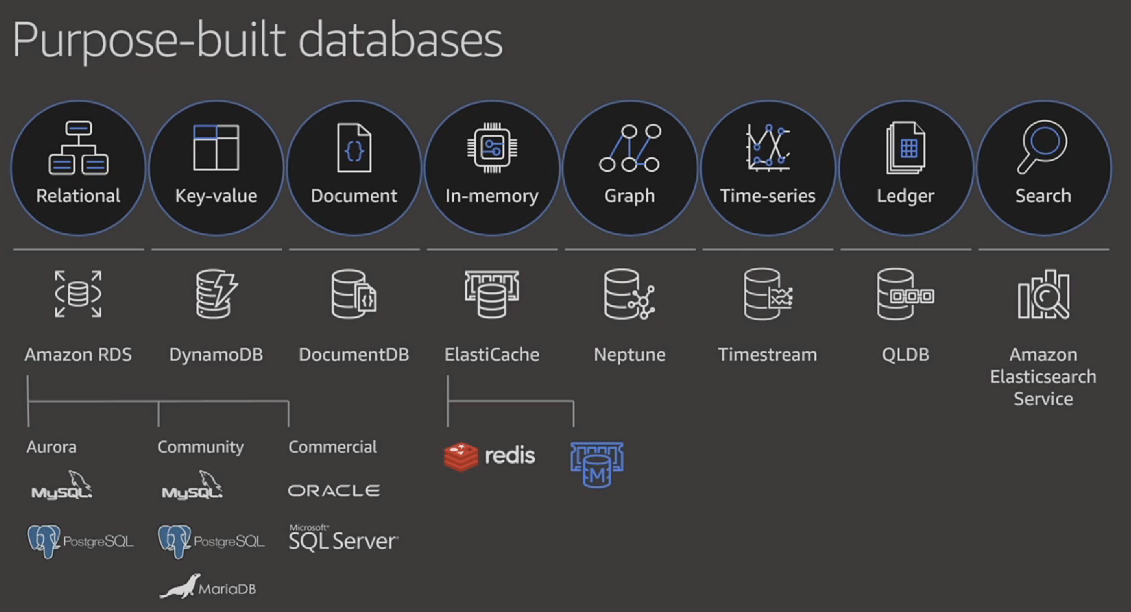
Deciding on the database to use for our application or workload can be very tricky. Since I join AWS Community Builder, I spend a least 1 hour every day exploring AWS services based on use case. Amazon Web Service(AWS) provides several options for Databases, we can be confused on the right one to choose. This article is a documentation of what I learned and the resources I used in understanding the various databases in AWS and how to decide when to use them. I hope it will be of value to you. I will like to have feedback on what you think I should add or remove or improve on as I continue exploring AWS and other cloud services.
There are a lot of criteria the could help us in selecting the right database in AWS, to make it easier for us, we summarize it into the following 4 criteria
- Type of Data
- Size of Data
- Structure or Shape of Data
- Activities that will be done on the Data
Now that we have an idea of the criteria required in selecting the database, let us dive into each of these databases. All databases in AWS are known to have the following properties
- fully managed by AWS
- scalable that is increase and decrease based on demand
- highly available that is the databases are guaranteed to be always up
Relation Databases
Amazon Relational Database Service(RDS)

Amazon RDS is not a database itself instead it is used to set up, operate, and scale relational databases in the cloud. It enables us to provisioning Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server. It is like an administrator for these databases. It automates failover, backups, restore, disaster recovery, access management, encryption, security, monitoring, and performance optimization. It has two major backup solutions which are automated backups and manual snapshots. It has a maximum of 5 replicas. Its replicas can be multi-availability zone replica, cross-region replicas, and read replica. But the resources aren’t replicated across AWS Regions by default expect you set it specifically.
When to use Amazon Relational Database Service(RDS)
If we need to use any of these six databases Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server.
Pricing
Amazon Relational Database Services(RDS) pricing depends on either we are using it On-Demand or Reserved Instances.
Official Resources
Amazon Relational Database Services(RDS)
Other Resources
AWS Certified Solutions Architect - Associate 2020 (6:23:16 - 7:00:11)
Amazon Relational Database Service (Amazon RDS) by Vlad Vlasceanu
Amazon Relational Database Service (RDS) (DAT302) by Brain Welcker
Amazon Aurora
Amazon Aurora has MySQL and PostgreSQL compatibility, it is five times faster than standard MySQL and three times faster than standard PostgreSQL database. Amazon Aurora is 90% cheaper than standard MySQL and PostgreSQL databases. It has a maximum size of 128 TB. Amazon Aurora defines a scaling policy of a maximum of 15 Aurora Replicas. Aurora Backup and Failover are automatic. Amazon Aurora supports cross-region replication. Aurora MySQL DB Cluster and PostgreSQL are created using the Amazon Relation Database Service console. Aurora Serverless gives Amazon Aurora the ability to automatically scale up, scale down, start-up, and shut down(auto-scaling). Aurora Serverless is best used when building an application that is not frequently used, building a new application, building an application with varying and unpredictable workloads.

Parallel Query for Amazon Aurora - source
Pricing
Amazon Aurora Pricing is based on either we select the MySQL edition or the PostgreSQL edition. Aurora Serverless is charged based on Aurora Capacity Unit(ACU)
Official Resources
Other Resources
AWS re:Invent 2019: [REPEAT] Amazon Aurora storage demystified: How it all works (DAT309-R) by Murali Brahmadesa and Tobias Ternström
Amazon Aurora Global Database Deep Dive by Aditya Samant
AWS Certified Solutions Architect - Associate 2020 (7:02:14 - 7:06:56)
Amazon Aurora ascendant: How we designed a cloud-native relational database
Data Warehousing
Amazon Redshift
Amazon Redshift is columnar storage used for data warehousing, it is used to analyze and get insight from large data quickly by executing complex queries on them. These data are usually at rest and historical data. It contains a cluster of nodes, it could be in single-node mode or multi-node mode. There are two types of nodes in Amazon Redshift, namely leader node and compute node. The leader node stores SQL endpoints, metadata, and coordinates parallel SQL processing. Compute nodes stores the data, and execute the queries. Amazon Redshift stores data on a single Availability Zone. Amazon Redshift spectrum is used to query Amazon Simple Storage Service(Amazon S3) directly. Amazon Redshift federated queries enables us to query and analyze live data across databases, data warehouses, and data lakes.

Amazon Redshift Architecture - source
When to use Amazon Redshift
for Online Analytical Processing
if we need to run queries across multiple data sources. For instance, we can copy data from different storages like Amazon EMR and Amazon S3 into Amazon Redshift.
Amazon Redshift is suitable for generating reports for business intelligence
Pricing
Amazon Redshiftp pricing - the basic price for Amazon Redshift starts from $0.25 per hour. There are several other features that can influence the price such as Amazon Redshift Spectrum pricing, Concurrency Scaling pricing, Redshift managed pricing, and Redshift ML pricing.

Official Resources
Other Resources
AWS re:Invent 2017: Best Practices for Data Warehousing with Amazon Redshift & Redsh (ABD304) by Tony Gibbs
Getting Started with Amazon Redshift - AWS Online Tech Talks by Greg Khairallah and Harshida Patel
Amazon Redshift Tutorial | Amazon Redshift Architecture | AWS Tutorial For Beginners | Simplilearn
Amazon Redshift Tutorial | AWS Tutorial for Beginners | AWS Certification Training | Edureka
AWS Certified Solutions Architect - Associate 2020 (7:07:58)
What is Amazon Redshift? By Kevin Goldberg
NoSQL - Key/Value
DynamoDB
DynamoDB is a NoSQL database, key/value, and document database. That is it support document and key/value structures. DynamoDB’s major components are tables, items, attributes, keys, and values. A table is a collection of items and an item is a collection of attributes. Items are similar to rows while attributes are similar to columns in a traditional database. A key is used to identify attributes and value is the data itself. The Major API components in DynamoDB are control plane, data plane, DynamoDB streams, and transactions. On-Demand and Provisioned Mode are the read/write capacity modes in DynamoDB. Amazon DynamoDB provides us the ability to specific our Provisioned capacity based on Read Capacity Units(RCU) and Write Capacity Units(WCU). Amazon DynamoDB creates partitions based on size, Read Capacity Units and Write Capacity Units. The criteria required for partitioning are size of 10GB, RCU of 3000, and WCU of 1000. Encrypt data at rest (that is inactive data), data that is not moving from one device to another or from one network to another. DynamoDB has a Point in time recovery feature that is we can restore your data to any point in time. Amazon DynamoDB Accelerator(DAX) enables us to manage write through cache on DynamoDB, it reduces response time from milliseconds to microseconds. Amazon DynamoDB uses SSD storage and stores its data across 3 different availability zone.

When to use Amazon DynamoDB
for Online Transaction Processing(OTP).
to store real-time data from an IoT device.
to store activities and events on a web application such as clicks.
to store items in a Web application like user profile, user events used by advertising, gaming, retail, finance, and media companies.
for Data that requires high request rate(millions of requests per seconds).
it is best used in situations that require high consistency.
Pricing
Amazon DynamoDB pricing depends on on-demand capacity mode and provisioned capacity mode.
Hands-On
Creating Tables and Loading Data
Sample Code
Create a ToDo Web App Storing your data in Amazon DynamoDB
Official Resources
Other Resources
AWS DynamoDB Tutorial | AWS Services | AWS Tutorial For Beginners | AWS Training Video | Simplilearn
AWS Certified Developer - Associate 2020 (5:05:21)
AWS re:Invent 2018: Amazon DynamoDB Under the Hood: How We Built a Hyper-Scale Database by Jaso Sorenson
AWS re:Invent 2018: Amazon DynamoDB Deep Dive: Advanced Design Patterns for DynamoDB (DAT401) by Rick Houlihan
Building a Mars Rover Application with DynamoDB
Document Database
Amazon DocumentDB
This is a document database that supports MongoDB. It has the capability to easily store, query, and index JSON data. It has about 15 read replicas and scales vertically with very low impact. It has flexible schema and Ad hoc query capability. It is easy to index and can be used for operational and analytics workloads.

Pricing
Amazon DocumentDB pricing is based on On-demand instances, database I/O, database storage and backup storage.
When to use Amazon DocumentDB
it is Amazon version of MongoDB, it is used when you need to run MongoDB at scale
best for Profile management, Content, and catalog management.
Official Resources
Amazon DocumentDB Documentation
Other Resources
AWS re:Invent 2019: Amazon DocumentDB deep dive (DAT326) by Joseph Idziorek and Antra Grover
Building with Amazon DocumentDB (with MongoDB compatibility) - AWS Virtual Workshop by Meet Bhagdev
DynamoDB vs AWS DocumentDB vs MongoDB
MongoDB vs. DocumentDB: Which Is Right for You?
Difference between AWS DynamoDB vs AWS DocumentDB vs MongoDB?
Graph Database
Amazon Neptune
Amazon Neptune is a graph database, it works with highly connected datasets. It checks for relations or similarity in data. For instance similarity between the movies a user watches on Netflix. It components are node(data entities), edges(relationships) and properties. Amazon Neptune support property graph like open-source Apache TinkerPop Germlin and Resource Description Framework(RDF) SPARQL. Amazon Neptune replicates data 6 times across 3 Availability Zones. Amazon Neptune Streams can be used to capture changes in a graph.

Pricing
Amazon Neptune pricing is influenced by On-demand instances, database I/O, database storage, backup storage and data transfer.
When to use Amazon Neptune
Amazon Neptune is best used when we have relationships in the data.
for recommendation engines, fraud detection, and drug discovery.
for knowledge base applications such as Wikidata.
for identity graphs to show unified view of customers and prospects based on their interactions with a product or a website.
for social Networking applications to store user profiles and interactions.

Official Resources
Other Resources
AWS re:Invent 2019: Deep dive on Amazon Neptune (DAT361) by Bradley Bebee, Karthik Bharathy, and Ora Lassila
Nike: A Social Graph at Scale with Amazon Neptune
Homesite: Event-Driven Data Analytics Platform Using Amazon Neptune
AWS on Air 2020: AWS What’s Next ft. Amazon Neptune ML
In memory
Amazon ElastiCache
Amazon ElastiCache use to manage in-memory caching. Caching is storing data in a temporary storage area. This data is stored on the RAM which is volatile, that is the data can get lost easily and can be accessed fast. It stores frequently accessed data to improve performance, this helps to avoid application latency and throughput. It caches data from the database which is different from CloudFront(Content Delivery Network). Amazon ElastiCache stores important data in memory. Amazon Cloudfront stores static files, for example, HTML, audio, video, media files required by a web app. Amazon ElastiCache access only resources in the same VPC.

Amazon ElastiCache has two engines
- Amazon ElastiCache for Redis
- Amazon ElastiCache for Memcached.
Pricing
Amazon ElastiCache pricing is based on the node types, backup storage, and data transfer.
When to use Amazon ElastiCache
it is best used when you need microseconds latency, key-based queries, and specialized data structures.
for situations like leader boards and real-time caching
if the data is on every page load or every request.
Official Resources
Amazon ElastiCache for Redis Documentation
Amazon ElastiCache for Memcached Documentation
Other Resources
AWS re:Invent 2019: Supercharge your real-time apps with Amazon ElastiCache (DAT208) by Pratibha Suryadevara
AWS re:Invent 2018: ElastiCache Deep Dive: Design Patterns for In-Memory Data Stores (DAT302-R1) byMichael Labib
AWS Certified Solutions Architect - Associate 2020(8:38:40)
Time series
Amazon Timestream
Amazon Timestream is a serverless time-series database for IoT and operational applications. Time series data are recorded over a period of time such as stock data and temperatures of a device. Amazon Timestream can be used to store and analyze trillions of events per day up to 1,000 times faster and at as little as 1/10th the cost of relational databases. One major advantage of Amazon Timestream database is its capability to move historical data to low-cost storage(magnetic store) but retain recent data(hot data) in-memory(SSD store). Queries can be run on both historical data and recent data. In addition, Amazon Timestream has a built-in time-series analytics function such as smoothing, approximation, and interpolation which helps in detecting patterns in data. Major concepts on Amazon Timestream are record, dimension, measure, timestamp, table, and Database. Records cannot be deleted or updated.

Pricing
Amazon Timestream pricing is based on writes, SSD store, magnetic store, data transfer and queries.
When to use Amazon Timestream
for time series data from IoT devices
collecting and analysing operational metrics
analytical application
Sample code
Getting started with Amazon Timestream with Python
Official Resources
Amazon Timestream Documentation
Other Resources
Getting Started with Amazon Timestream by Tony Gibbs
Deep Dive on Amazon Timestream by Tony Gibbs
Ledger Database
Amazon Quantum Ledger Database(QLDB)
Amazon QLDB is a fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log owned by a central trusted authority. It is used to track data changes in applications. It can be used for storing audit logs. It uses a SQL like language called PartiQL. It is immutable, transparent, cryptographically verifiable, and serverless.

Pricing
Amazon Quantum Ledger Database(QLDB) pricing is based on the data transfer, data storage and I/O.
When to use Amazon QLDB
best suited for economic and financial record
for application data
used in finance for tracking credit and debit transactions
for HR systems to track employee payroll, bonus, benefits and other details
for manufacturing to track product manufacturing history
Official Resources
Amazon Quantum Ledger Database(QLDB)
Amazon Quantum Ledger Database Documentation
Amazon Quantum Ledger Database Blog
Other Resources
AWS re:Invent 2019: Amazon QLDB: An engineer’s deep dive on why this is a game changer (DAT380) by Andrew Certain
Building System of Record Applications with Amazon QLDB - AWS Online Tech Talks by Philip Simko and Michael Labib
Other resources on selecting the right database
AWS re:Invent 2017: [REPEAT] Which Database to Use When? (DAT310-R) by Tony Petrossian and Ian Meyers
Selecting the Right Database for Your Application by Joseph Idziorek
Choosing The Right Database by Randall Hunt
Whoa, so many databases and terminologies. I am sure you need a break. I hope you were able to understand the different databases in AWS, when to use them, and resources that will give you a deep dive.

Comments