8 min to read
Introduction to Big Data Technologies 2:HDFS, YARN and MapReduce
In my first article in this series Introduction to Big Data Technologies 1: Hadoop Core Components, I explained what is meant by Big Data, the 5 Vs of Big Data, and brief definitions of all the major components of Hadoop ecosystem. In this article, we will be diving into 3 backbones of Hadoop which are Hadoop File System(HDFS), Yet Another Resource Negotiator(YARN), and MapReduce. We will also do an hands on example of MapReduce on the European Football Club Market Value dataset, we will use the concept of MapReduce to find the frequency of the age of players in European Football Clubs.
Hadoop File System(HDFS)
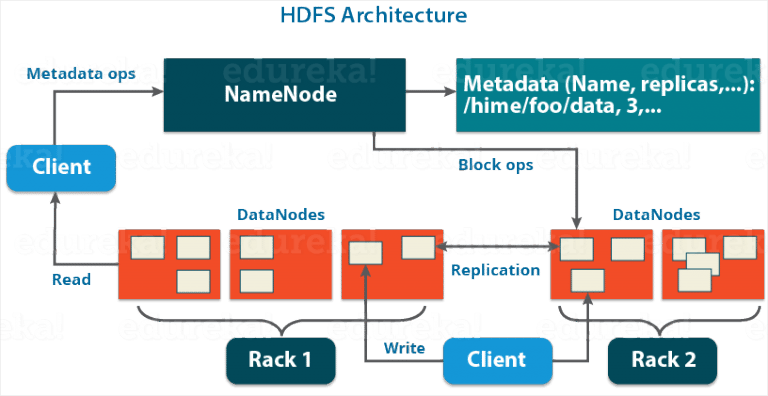
HDFS is the storage layer in Hadoop. It stores large files by splitting them into blocks, each block is stored in a distributed manner, that is on different storage location across a cluster of machines. This helps in analyzing and processing the data quickly. The default block size in Hadoop 2.X is 128MB. Since the different blocks are store parallelly and distributedly, these blocks can also be processed parallelly and distributedly. Each block is replicated to make the system fault tolerance and highly available. Note it is not best for storing small data because it results in a lot of overhead. The major components of HDFS are NameNode and DataNodes. The DataNodes are stored in racks, distributed systems contain several racks. HDFS has a Master/ Slave Architecture, where the NameNode is the master and the DataNodes are the slaves.
Terms in distributed systems
Fault tolerance – this the ability for a system to continue functioning properly despite the failure of some of its components. High availability - is the ability of a system to minimize downtime, that is the system is always up. It is measure by the percentage of total uptime. Replication – this involves replicating the same block of data on difference Data Node. Rack Awareness Algorithm - is used for managing the storage of blocks into different racks. This states that a replica of a block cannot be stored in the same rack.
Components of HDFS
NameNode – stores the metadata of DataNodes and the blocks storage in them. For instance the location of the blocks on the DataNodes, the replicas of the blocks, newly created blocks, modified blocks, deleted blocks, heartbeat and reports of all DataNode, etc. It maintains and manages DataNodes. DataNode – stores the actual block of data. DataNode communicates with each other to create and maintain replicas of blocks. The client read and write blocks to the DataNodes.
Reading a file in HDFS
- The Client sends a request to the NameNode to read a file.
- The NameNode returns the storage location (IP Addresses) of the blocks of that file on the DataNodes.
- The Client reads for blocks in the DataNodes based on the locations received from the NameNode.
Writing a file in HDFS
- The Client sends a request to write blocks of a file to the NameNode.
- The NameNode returns the IP addresses of storage locations where the blocks can be stored on DataNodes.
- The client stores the blocks of data in the DataNodes based on the IP addresses it received from the NameNode.
- DataNodes communicate with each other to replicate the blocks.
- Once the replicas are created successfully, the DataNodes send a success message to the client.
- Then the client sends the success message to the NameNode.
- The NameNode updates the metadata of the DataNodes and the blocks.
- Blocks are stored in parallel while replicas are store in a sequentially.
HDFS Command
HDFS commands are similar to normal Linux commands, the only addition is that you have to put “hadoop fs” before each command.
List file and directories in a directory

Make new directory

Copy file from local device to HDFS

YARN – Yet Another Resource Negotiator
It is the resource manager used in Hadoop 2.X. It supports multiple processing model It manages how processes are done in Hadoop. It contains Resource Manager and Node Manager.

Resource Manager
It manages the resources in the NodeManger. It contains the scheduler and the Application Manager. The scheduler is responsible for allocating resources to various running applications. Application Manager manages the list of submitted tasks. The application manager receives the request from the client, negotiate with the container in the NodeManager on the required resources for executing the task.
NodeManager
NodeManager is on every DataNode that is where the data are stored. The Node manager executes the task on the data. It contains application Master and container. The Application Master manages application lifecycle, manages execution flow, and executes the task. Application Master request for resource s from the resource manager. The Container provides the execution environment.
MapReduce
MapReduce is a model used for processing large data distributedly and parallelly which is cheap, reliable, and fault tolerance. In HDFS, the files are already stored in different storage locations. MapReduce process these data on those locations then returns an aggregated result. MapReduce functions can be writing in different programming languages like Python, Java, and Scala. The fastest of them is Scala. MapReduce process data locally, that is data are processed where they are stored. This makes processing data faster. The result from each node are aggregated by the master node, then the final result is sent to the client. MapReduce view inputs and outputs as key, value pairs.
MapReduce Workflow
Using the European Football Market values Dataset on Kaggle, Contains web scrapped Market Value information and other related data on Players from the top 9 European leagues including Premier League, La Liga, Liga NOS, Ligue 1, Bundesliga, Seria A, Premier Liga, Eredivisie, and Jupiler Pro League. The dataset contains 35 columns and over 4200(rows) player details but we will focus on the 6th column which contains the age of the players. Let us use the instance of the 6 players and 4 columns.

Splitting - The data is divided into blocks.
Block 1

Block 2
 Block 3
Block 3

Mapper - takes a set key-value pairs as input, transforms them, and returns another set of key-value pairs. Mappers focus on transforming input. In this example select the Age column and create another column that represents the count of a single player which is always 1.



Shuffling and Sorting – this is done automatically by MapReduce, it shuffles and sorts the output of the mapper based on keys.





Reducer – takes in a set of key-value pairs as input, performs some operation on them like sum, count, average, etc, then return reduced data. Reduce focus on aggregating input.




Final output

Code Example
- Download and install Virtual Machine Oracle VirtualBox
- Download Hortonworks HDP Sandbox
-
Import and start your Hortonworks on your Virtual Machine, it installs cent OS and Hadoop dependencies on the virtual machine.

- On windows, download Putty to create a terminal you can use in connecting to your virtual machine. You can connect directly from the terminal on Mac and Linux.
Host Name – maria_dev@127.0.0.1
Port - 2222
- Login on the terminal using
Username – maria_dev
Password – maria_dev
- Install dependencies
- Install pip, mrjob and editor like VS Code, nano, vim, sublime
-
Download European Football Market Value from Kaggle. You can upload the data on Google Drive or a server because you cannot automatically use wget to download data from Kaggle.
-
Download data to the Virtual machine

-
Create a python file with your editor

-
Run the python file using virtual machine resources

- Run-on Python file using Hadoop cluster

Comments