10 min to read
Introduction to Big Data Technologies 1: Hadoop Core Components

I am sure you use a social media platform either Facebook or Instagram or Twitter or Snapchat or Tiktok, the list is endless. One thing that is common to all these platforms is data generation. While using this platform, we generated a lot of data by commenting, uploading pictures and videos, clicks, likes, the time we spend on them, the location we are login in from, etc. In 2018, Forbes stated 2.5 quintillion bytes of data was generated every day. As of January 2019, the internet reaches 56.1% of the world population which represents 4.49 billion people a 9% increase from January 2018. With the Pandemic in 2020, the use of the internet and the generation of data has increased tremendously.
This article focuses on introducing you to big data and to the core component of Hadoop which is the main technology behind Big Data.
Before we continue, we need to understand what Big Data really is and some concept in Big Data.
What is big data?
According to Wikipedia Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. In lame man’s words, Big Data is a way of analyzing and processing this large amount of data generated every day. For example, Facebook processes and analyses data about us to show us personalized advertisements.
To fully understand the importance of Big data, we need to understand the 5 Vs of big data.
5 Vs of big data
Volume is the size of data being generated. As explained earlier we generated a large amount of data every day. These data are obtained from smart(IoT) devices, social media platforms, business transactions, etc.
Velocity has defined in physics, is the rate of change, that is how something changes with respect to time. In Big Data, velocity is the rate at which new data is generated, in other words, the speed at which data is generated. With an increase in the population of people using the internet and the ability to do anything from the comfort of our home, the velocity at which data is generated has seen an unprecedented increase every year.
Variety involves the type of data. Data can be structured, semi-structured, and unstructured. Structured data are well defined, that is storing the data has some constraints. For instance, each column in the storage is well defined. An example is a relational database storing the bio of consumers. Semi-structured data have a few definitions like organization properties, examples are XML and JSON files. Unstructured data have no definitions, examples are data generated by an IoT device, social media post, etc. Another form of variety could also be the format of the data. I am sure when you save an image you have seen a format called PNG or JPG, this shows data in different formats. Data could be an image, video, text, audio, etc and each of these types also have several formats. A video could be in MP4 or 3GP and several other formats.
Veracity focuses on the accuracy and quality of the data. That is the inconsistency and uncertainty in the data. Since data is gotten from different sources, it is difficult to control the quality and accuracy of the data. For instance, my address on Facebook can be saved as Berlin Germany but I already moved to New York, USA. Gain
Value focuses on what we can gain from the data. That is the insight that can be obtained from the data. The useful information that can be extracted from the data.
So much about Big Data, now let us dive into the technologies behind Big Data. The major technology behind big data is Hadoop.
History of Hadoop

Hadoop core components source
As the volume, velocity, and variety of data increase, the problem of storing and processing the data increase. In 2003 Google introduced the term “Google File System(GFS)” and “MapReduce”. Google File System(GFS) inspired distributed storage while MapReduce inspired distributed processing. GFS provides efficient and reliable access to data. GFS divides a large file to small chunks, each chunk is stored and processed by different computers, then the result from each computer is accumulated together to give a final result. Hadoop was inspired by GFS, it started as a project called “Nutch” in Yahoo by Doug Cutting and Tom White in 2006. The name “Hadoop” was derived from Doug Cutting kid’s toy, a stuffed yellow elephant.
Hadoop is an open-source software platform for distributed storage and distributed processing of very large datasets on computer clusters built from commodity hardware - Hortonworks
Two major words in this definition are distributed storage and distributed processing. Hadoop File System(HTFS) manages the distributed storage while MapReduce manages the distributed processing.
Hadoop Core Components
Data storage

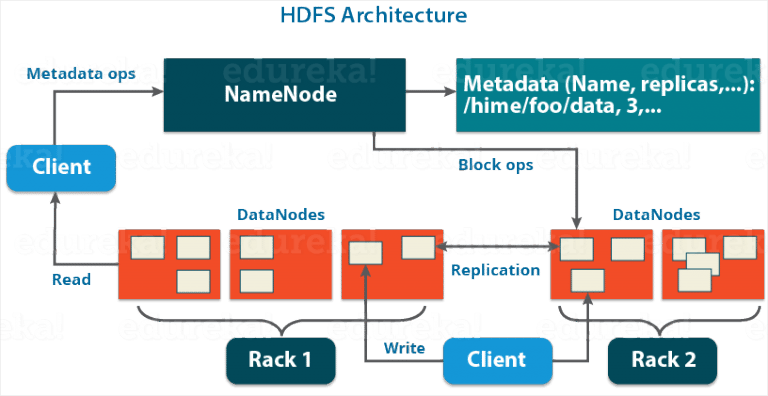
Hadoop File System(HDFS) is an advancement from Google File System(GFS). It is the storage layer of Hadoop that stores data in smaller chunks on multiple data nodes in a distributed manner. It also maintains redundant copies of files to avoid complete loss of files. HDFS is similar to other distributed systems but its advantage is its high tolerance and use of low-cost hardware. It contains NameNode and DataNodes.
Data Processing

Mapreduce is a programming technique in Hadoop used for processing large amounts of data in parallel. MapReduce is divided into two phases, first is the map phase where Mappers transform data across computing clusters and second is the reduce phase where reducers aggregate the data together.
Cluster Resource Management

Yet Another Resource Negotiator (YARN) is used for managing resources of clusters of computers. This is the major difference between Hadoop 1.0 and Hadoop 2.0, it is the cluster manager for Hadoop 2.0. It’s advantage is separating MapReduce from resource management and job scheduling.

Mesos is used for handling workload in a distributed environment through dynamic resource sharing and isolation. It is used for managing the entire data center.

Tez is used for building high-performance batch and interactive data processing applications coordinated by YARN in Hadoop. It allows complex Directed Acyclic Graph(DAG). It can be used to run Hives queries and Pig Latin scripts.
Scripting

Pig is a high-level API that is used for writing simple scripts that looks like SQL instead of writing in python or Java. It runs on Apache Hadoop and executes Hadoop jobs in Map Reduce, Apache Tez, or Apache Spark. Pig contains a Pig Latin script language and runtime engine.
Query

Hive is a data warehouse software built on Apache Hadoop, this is similar to PIG. It helps in reading, writing, and managing large datasets in a distributed storage using SQL like queries called HQL(Hive Query Language). It is not designed for online transaction processing(OLTP), it is only used for Online Analytical.

Drill is a distributed interactive SQL query engine for Big data exploration. It queries any kind of structured and unstructured data in any file system. The core component of Drill is Drillbit.
 Impala is an MPP(Massive Parallel Processing) SQL query engine for processing large amounts of data. It provides high performance and low latency compared to other SQL engines for Hadoop.
Impala is an MPP(Massive Parallel Processing) SQL query engine for processing large amounts of data. It provides high performance and low latency compared to other SQL engines for Hadoop.

Hue is an interactive query editor then provides a platform to interact with data warehouses.
NoSQL

HBase is an open-source column-oriented non-relational distributed(NoSQL) database modeled for real-time read/write access to big data. It is based on top of HDFS, it is used for exposing data on clusters to transactional platforms.
Streaming

Flink is an open-source stream processing framework, it is a distributed streaming dataflow engine. It is a stateful computation over data streams. It integrated query optimization, concepts from database systems, and efficient parallel in-memory and out of core algorithms with the MapReduce framework.

Storm is a system for processing streaming data in real-time. It has the capability of high ingestion rate. It is very fast and processes over a million records per second per node on a cluster of modest size. It contains core components called spout and bolt.

Kafka is also a real-time streaming data architecture that provides real-time analytics. It is a public-subscribe messaging system that allows the exchange of data between applications. It is also called a distributed event log.
In-memory processing

Ignite is a horizontally scalable, fault-tolerant distributed in-memory computing platform for building real-time applications that can process terabytes of data with in-memory speed. Ignite distribute and cache data across multiple servers in RAM to provide unprecedented processing speed and massive application scalability.

Spark - is an analytics engine for large -scale data processing.It creates a Resilient Distributed Dataset(RDD) which helps it to process data fast. RRDs are fault tolerance collections of elements that can be distributed and processed in parallel across multiple nodes in a cluster.
Workflow and Schedulers

Oozie is a workflow scheduler for Hadoop, it is used for managing Hadoop jobs in parallel. Its major components are workflow engine for creating Directed Acyclic Graphs(DAG) for workflow jobs and coordinator engine used for running workflow jobs.

Airflow is a workflow management platform, it is used to create, manage, and monitor workflow. It also uses a Directed Acyclic Graph(DAG).
Data Ingestion

Nifi is used for automating the movement of data between disparate data sources.

Sqoop is used for transferring data between Hadoop systems and a relational database. It is a connector between Hadoop and legacy databases. http://new.skytekservices.com/sqoop

Flume is used for data ingestion in HDFS, it is used to collect, aggregate and transport large amounts of streaming data to HDFS. https://flume.apache.org/
Coordination

Zookeeper is used for coordinating and managing services in a distributed environment, it is used for tracking nodes.
Management and Monitoring

Ambari shows an overview of a cluster. It gives a visualization of what is running on the clusters, the resources used on the clusters, and a UI to execute queries.
Machine Learning

Madlib used for scaling in database analytics, it is used to provide parallel implementation to run machine learning and deep learning workloads.

Mahout is a distributed linear algebra framework and mathematically expressive Scala DSL design to quickly implement algorithms. It integrates scalable machine learning algorithms to big data.

Spark MLLiB solves the complexities surrounding distributed data used in machine learning. It simplifies the development and deployment of scalable machine learning pipelines
Security

Ranger is used for monitoring and managing data security across Hadoop platforms. It provides a centralized security administration, access control, and detailed auditing for user access with Hadoop systems.
Whoa, a lot of names, concepts, and technologies. I am sure you have been able to get an overview of the major components of Hadoop ecosystem. In the next series of articles, we will dive into the major components with real-life hands-on examples.

Comments