14 min to read
From Competition to Production: Deploying a Machine Learning Model on Azure
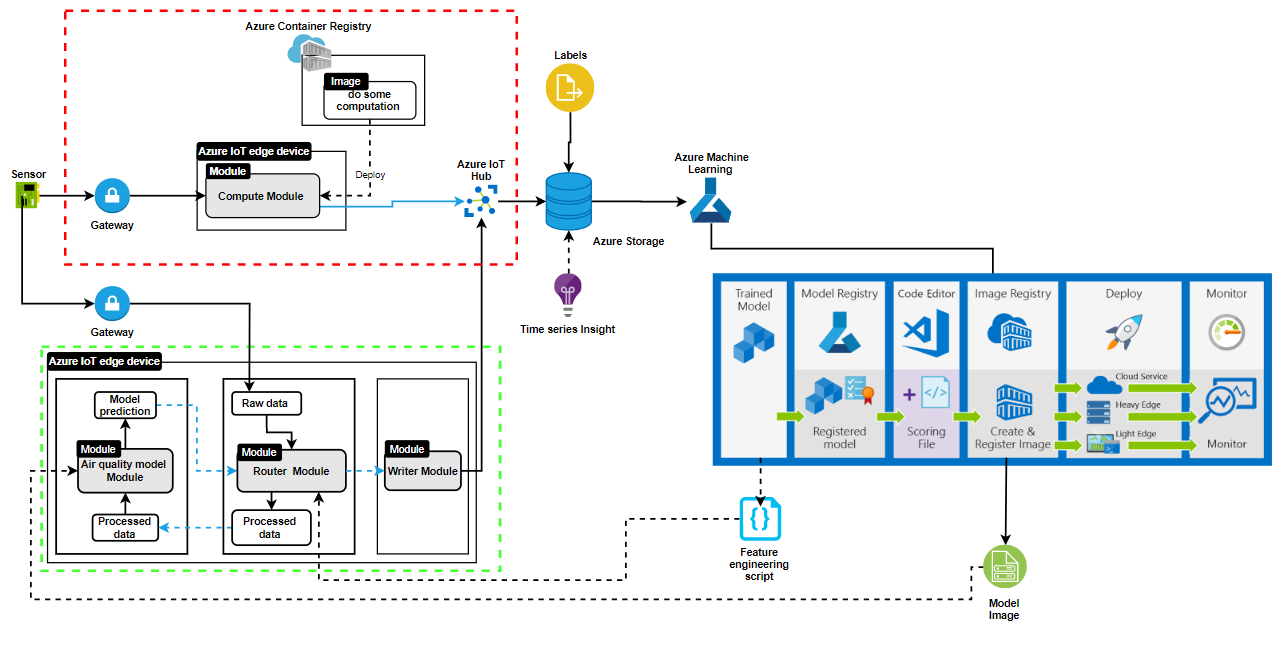
Architecture for deploying model on Azure
While building Machine Learning models, a lot of attention is put into getting the best accuracy. These supposed accurate models are not valuable until they are deployed into reality to solve problems. Most competitions Kaggle and Zindi platforms are focused on competing to get the best accuracy. I competed in AirQo Ugandan Air Quality Forecast Challenge to predict future air quality level in cities in Uganda. My model’s was one the top 100, and I decided to add more value to the competition by deployed it on Azure. This can help to extend the competition to solving a real-life problem.
This article describes all the steps involved in the lifecycle of a ML project using the competition as a use case. I used Microsoft Azure cloud services for deploying the model.You can find the details of the implementation on github.
Defining Project Goals
The goal of the AirQo Ugandan Air Quality Forecast Challenge on Zindi is to predict the air quality level of cities in Uganda at exactly 24 hours after a 5 day series of hourly weather data readings . To measure the air quality level, we need to know the mass of PM2.5 (particulate matter smaller than 2.5 micrometers in diameter or around 1/30th the thickness of a human hair strand) in a volume of air given by micrograms per cubic meters. These particles are not visible to human eye because they are exceedingly small. Tey are generated from vehicle exhaust, machines in industries, burning of fossil fuels, and others. Bad air quality causes respiratory diseases, heart diseases, and stroke.
Choose the project task
The project can be formulated as solving any of the following tasks.
- Classification: If the level of air quality has been divided into different classes for instance good, moderate, unhealthy for sensitive groups, unhealthy, very unhealthy, and hazardous, the task could be to assign a task to a location.
- Regression: If the task is to predict the PM2.5(a continuous variable).
- Clustering: If the task is to cluster cities with similar air quality levels.
- Anomaly detection: If the task is to monitor sudden changes in the air quality level.
- Forecasting: If the task is to predict the air quality level for the future.
Formulating this challenge as a forecasting task since we are asked to predict the air quality level at exactly 24 hours after a 5-day series of hourly weather data readings is the best choice.
Data Collection
Measuring PM2.5 which affects the air quality level of place requires gathering data from several sensors. For the Ugandan Air Quality challenge, they used 5 sensors to get the following data every hour:
- Temperature(temp): mean temperature recorded at the site over an hour, measured in degrees Celsius.
- Precipitation(precip): total rainfall recorded over an hour, measured in millimeter.
- Wind Direction(wind_dir): mean direction of wind over an hour, measured in degrees.
- Wind Speed(wind-spd): mean of the speed of wind over an hour, measured in meters per second.
- Atmospheric Pressure(atmos_press): mean of atmospheric pressure over an hour, measured in atm.
For each of these sensors used, metadata containing the features of the sensors (location, height above sea level…) was collected. You can find the details here.
Data Ingest
This section refers to the red dotted box in the “architecture for deploying model on Azure” image above.
Data ingestion is a process of moving data from one or more sources to a destination where it can be stored and further analyzed. In this use case, we need to collect the data from the sensors and store them in a data storage. We will be use Azure data storage container to store the data. To understand this section well, we need to understand some terms in Azure
- Azure IoT Edge: this is used to move cloud analytics and custom business logic to devices so that you can focus on business insights instead of data management. It consists of IoT Edge modules, IoT Edge runtime, and cloud-based interface.
- IoT Edge modules are containers that run Azure services, third-party services, or our own code. Modules are deployed to IoT Edge devices and execute locally on those devices.
- IoT Edge runtime runs on each IoT Edge device and manages the modules deployed to each device. It also performs management and communication operations.
- Cloud-based interface enables you to remotely monitor and manage IoT Edge devices.
- IoT Hub: is a managed service hosted in the cloud that acts as a central message hub for bi-directional communication between our IoT application and the devices it manages.
- Time Series Insight(preview): is used to collect, process, store, analyze, query data from Internet of Things (IoT) and scale data that’s highly contextualized and optimized for time series.
- Azure gateway: we use a transparent gateway configuration that allows devices to connect to Azure IoT Hub through the gateway without knowing that the gateway exists. A gateway is used for sending encrypted traffic.
- Azure Container Registry: is used to store and manage your Docker container images and related artifacts. In the diagram, the data ingestion part involves the section in the red dotted box. For the project, we will connect our sensors to the IoT edge device through a gateway. Azure IoT runtime in the IoT Edge also manages a secure connection to our sensors, installs and updates workloads on the sensors, remotely monitors the sensors and other communication to our sensors. We register each sensor on the IoT hub to identify each sensor, then we get an image that triggers some computation on the data from the azure container registry and deploy it in an IoT edge module. This is just a high-level view of the workflow between a sensor, an Azure IoT edge device, and an Azure IoT Hub. We could also deploy Azure Functions or Azure Stream Analytics and Azure Machine Learning as a module to the Azure IoT edge device.
The data in Azure IoT Hub is routed to Azure storage. Azure has several storage types depending on our use case. In our case, we will use a blob storage container for storing massive unstructured data coming from our sensor. There is also Azure Cosmos DB use for multi-model database services like Mongo DB and Cassandra, etc.
")
Labeling
In the section, we add labels to the data we will use in training our model. Most of the time this is done manually, the quality and accuracy of the label affect the accuracy of our model so we need to pay a lot of attention to it.
Building and Training Model
At this point, we should have our labeled data stored in our storage account blob container, and they are well labeled. We need to query the storage account to provide 5-day series of the hourly data sent from the sensors. We are to follow the following steps, most of which are common in the data science life cycle, I also added other steps specific to Azure Machine Learning lifecycle.
- Create a workspace
- Download data from storage account
- Load and explore data
- Create Azure compute target
- Create feature engineering script
- Build model
- Create an environment and train a model
- Build and train a model
- Register the model
To perform the above steps, you need to understand the following Azure terms used in Machine learning
Azure ML Workspace is a dedicated platform for data scientists to manage data science workflow. It coordinates all resources and steps in building, testing and deploying a machine learning model.
Compute target is a computing resource used for training machine learning models, it helps in creating environments for training your model. It could be your local machine or a cloud-based resource.
Estimator is used for managing a machine learning experiment, it contains all the package dependencies required to run an experiment.
Create a workspace
There are several ways of creating a workspace on Azure. We can use the command line, Azure SDK or the Azure Portal. In my case I used Azure SDK, the code snippet is written below
from azureml.core import Workspace
ws = Workspace.create(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group,
create_resource_group=True,
location=location)
Download data from storage account
In the case of this competition, the dataset was already provided. All we needed to do was to create a storage account then upload the train and test data to the storage account container. In reality, our data will already be in the storage container which was routed from the IoT hub. We used the code below to retrieve the data from the storage account and download it into our workspace for easy access to the model.
from azureml.core import Datastore
ds = Datastore.register_azure_blob_container(workspace=ws,
datastore_name='airquality',
container_name=STORAGE_ACCOUNT_CONTAINER,
account_name=STORAGE_ACCOUNT_NAME,
account_key=STORAGE_ACCOUNT_KEY,
create_if_not_exists=False)
Load and explore data
As we know in machine learning, raw data are always very messy. We need to understand the correlation between features in the dataset, visualize the data to get some insight from the data, and understand the distribution of the data. I will not go in-depth into that since it is a popular concept in Machine learning and there are a lot of resources that have done a comprehensive explanation.
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
cluster_name = "air-quality-comp"
try:
# Check for existing compute target
compute_target = ComputeTarget(workspace=ws, name=cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
# If it doesn't already exist, create it
print('creating a new compute target ...')
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=3)
compute_target = ComputeTarget.create(ws, cluster_name, compute_config)
# can poll for a minimum number of nodes and for a specific timeout.
# if no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current BatchAI cluster status, use the 'status' property
compute_target.status.serialize()
Create feature engineering script
This is also a common process in machine learning. I created a script to handle the nan values, remove and add other features. We will import this script while building the model. This script will also be used for cleaning and transforming the raw data during training and inferencing.
Build model
In this project, we will use the CatBooostRegressor model, 20-fold cross-validation, 2500 estimators, learning rate of 0.3, and root mean square error as a metric to evaluate the model.
Create an environment and train a model in it
We create an environment using the estimator class then we install some packages like catboost, joblib, and scikit-learn. These packages are important to run our models. Thereafter we run our training script in the environment. We can make some changes in our model, do hyperparameter tuning then run the experiment again. We can have several runs in an experiment. We will register the best model which will be deployed later. We can also register several models then decide the version of the registered model to deploy.
Testing and deploying
At this point, we have a trained model. We need to test the model with the test set to check how accurate our model is, then deploy the model to test on real-life data. We will go through the following steps:
- Make predictions with register model
- Create a scoring script
- Create an inference environment
- Create a docker image
- Deploy the model
Make predictions with register model
We make predictions with our saved model using the predict method. But we need to remember to run the feature engineering script to clean the data before calling the predict method to test our test data..
Create a scoring script
The scoring script is used for inferencing. After deploying the model as a service, the script loads the model and returns the predictions for the submitted data. The script contains two major methods. First, is the init() method which is called when the service is initialized. The second method is the run(raw_data) which takes the data we want to predict as an argument. This script can be run inside a container which can then be deployed as a web service or Azure IoT Edge module.
def init():
global model
model_path = Model.get_model_path(model_name = '<<modelname>>')
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
def run(raw_data):
log_for_debug("raw_data", raw_data)
message_data = unpack_message(raw_data)
log_for_debug("message_data", message_data)
X_data = extract_features(message_data)
log_for_debug("X_data", X_data)
# make prediction
y_hat = model.predict(X_data)
response_data = append_predict_data(message_data, y_hat)
return response_data
Create inference environment
Previously we created an environment to train the model, we also need to create an environment to deploy the model. This environment will be created as a YAML file, it contains all the dependencies required to run the model in production.
Create a docker image
Create a docker image using the Azure core image class, this image contains the scoring script and the inference environment YAML file. While creating the image, we also include the model in the image.
Deploy the model
This involves the green dotted section in the “architecture for deploying model on Azure” image above. We have three modules in the Azure IoT device
- Air quality model module – This IoT edge module contains the image of the model. It received a clean / processed data from the Router module and predictions from the model. The predictions is sent to the router module.
- Router Module – This module receives the raw data from the device, processes the data using the feature engineering scripts, the processed data is sent to the Air quality model module to get predictions. It also receives back the prediction from the Air Quality model module. The prediction and the raw data are sent to the writer module.
- Writer Module – This module stores the prediction and the raw data gotten from the router module in the Azure storage.
Conclusion
Deploying a machine learning model is a critical aspect of a machine learning project that has always been overlooked. From this article, we went through each step in building an ML project using the Air quality challenge on Zindi and we were able to deploy our model on an IoT device for real-life prediction.

Comments