11 min to read
Automating machine learning lifecycle with AWS
This article explains Amazon Web Services (AWS) cloud services used in different tasks in a machine learning life cycle.

Machine Learning and data science life cycle involved several phases. Each phase requires complex tasks executed by different teams, as explained by Microsoft in this article. To solve the complexity of these tasks, cloud providers like Amazon, Microsoft, and Google services automate these tasks that speed up end to end the machine learning lifecycle. This article explains Amazon Web Services (AWS) cloud services used in different tasks in a machine learning life cycle. To better understand each service, I will write a brief description, a use case, and a link to the documentation. In this article, machine learning lifecycle can be replaced with data science lifecycle.
Data Acquisition
Streaming Data
Streaming data are acquired continuously in small sizes. Streaming data are real-time time data. Examples are data from social media, purchase activities on eCommerce platforms, and data from IoT devices. Amazon services used for streaming data is Amazon Kinesis.

Amazon Kinesis
Amazon Kinesis is used for capturing, processing, and analysing real-time streaming data. Amazon Kinesis can be divided into
Amazon Kinesis Video Streams - for capturing, processing, and storing video data for analytics and machine learning. This can be used for capturing video data during a video consultation on a web browser by a doctor, as explained in this article.
Amazon Kinesis Data Streams - collecting and processing large streams of data records in real-time. For example, real-time fraud detection as shown has explained in this article.
Amazon Kinesis Data Firehose - is used for providing real-time streaming data to Amazon S3, endpoints, and other destinations. For example, for automatically detecting sport highlights, you can refer to this article.
Amazon Kinesis Data Analytics aims to process and analyse stream data with SQL. For example, for processing credit card transaction data.In this article, machine learning lifecycle can be replaced with data science lifecycle.
Batch Data
Batch Data is historical data, in other words, data stored over a period of time. An example is customer transaction data stored over 1 year. Since batch data focuses on storing data. Next, we discuss data lake and databases in AWS that are used to store data.
Data Lake
Data Lake is used to store large amounts of data in its native format. Amazon S3 is used as a data lake.
Amazon Simple Storage Service (Amazon S3)
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. Amazon S3 is a data lake. It is similar to the hard drive on your computer with file folders but on the cloud. This is an example.
Databases
I wrote an article on selecting the right database in AWS.
 .
.
Data Processing
Data processing involves converting raw data to a format that can be used for machine learning and other processes. Amazon EMR and Amazon MSK are well-known services for processing data.
Amazon EMR (previously called Amazon Elastic MapReduce)
According to Amazon, Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark. Amazon EMR can be Amazon EMR on EC2, Amazon EMR on EKS, and Amazon serverless. It processes and analyzes vast amounts of data. In lane man’s words, it is used for processing big data in parallel. For example creating training data for machine learning.

// https://makeameme.org/meme/data-increased-by
Amazon MSK(Managed Streaming for Apache Kafka)
Amazon MSK enables you to build and run applications that use Apache Kafka to process streaming data. Essential components of Amazon MSK are broker nodes, zookeeper nodes, producers, consumers, topic creators, cluster operations. This can be used by a company that just became a unicorn and needs to process unicorn requests.
Data Cleaning and Wrangling
Data wrangling is the process of cleaning messy and complex data to a useable format.
Amazon SageMaker Data Wrangler (Data Wrangler)
SageMaker Data Wrangler is a feature of SageMaker Studio that provides an end-to-end solution to import, prepare, transform, featurize, and analyze and export data. This reduces the time to clean, aggregate, and prepare data for machine learning. This article explains how car charging stations data was cleaned and aggregated with sagemaker data wrangler.
Data Labeling
Data labelling involves adding informative labels for identifying raw data.
Amazon Sagemaker Data Labeling can be divided into SageMaker Ground Truth and SageMaker Ground Truth Plus.
Amazon SageMaker Ground Truth Plus
Amazon SageMaker Ground Truth Plus is a turnkey service that allows you to build high-quality training datasets at scale without using your own resources. Example of creating image data with sagemaker ground truth plus.
Amazon SageMaker Ground Truth provides the flexibility to build and manage your data labelling workflows and manage your own data labelling workforce. An example is text labelling for aspect-based sentiment analysis.
Data Visualization
Data visualization is the graphical representation of data. If a picture is worth a thousand words, data visualization is worth thousands of data points. There are a lot of visualization tools like Tableau and Power BI. The good thing about Amazon QuickSight for visualization is the easy integration with other Amazon services.
https://aws.amazon.com/quicksight/
Amazon QuickSight
Amazon QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people who you work with, wherever they are.
Feature Engineering
Feature Engineering is the process of converting raw data to features used to train machine learning models.
Amazon SageMaker Feature Store
Amazon SageMaker Feature Store is used for creating, storing, and sharing machine learning (ML) features. Feature stores can be online or offline. This blog explains how GoDaddy uses feature store in their machine learning life cycle.
Amazon SageMaker Notebook sagemaker
Amazon SageMaker Notebook SageMaker is a jupyter notebook connected to Amazon EMR for interactively exploring, visualizing, and preparing petabyte-scale data for machine learning (ML). It supports sharing your notebook with colleagues for collaboration through the UI.
Model Training
Model Training in Data science requires providing compute instances for machine learning.
Amazon Elastic Compute Cloud (Amazon EC2)
Amazon EC2 provides scalable computing capacity. Amazon EC2 eliminates your need to invest in hardware up front, so you can develop and deploy applications faster. The compute is scalable and resizable according to your workload.
Amazon Batch
AWS Batch is used for planning, scheduling and executing jobs on AWS compute services like AWS EC2, AWS Fargate and spot instance. Its provisions compute resources based on the job submitted.
SageMaker Training Compiler
SageMaker Training Compiler is a compute for more efficiently training deep learning(DL) models.
Hyperparameter Tuning
It is the process of selecting the best configuration and model for a machine learning task.
SageMaker Auto Tuning
SageMaker Auto Tuning automates the process of running several training jobs for selecting the best performing model.
Model Selecting
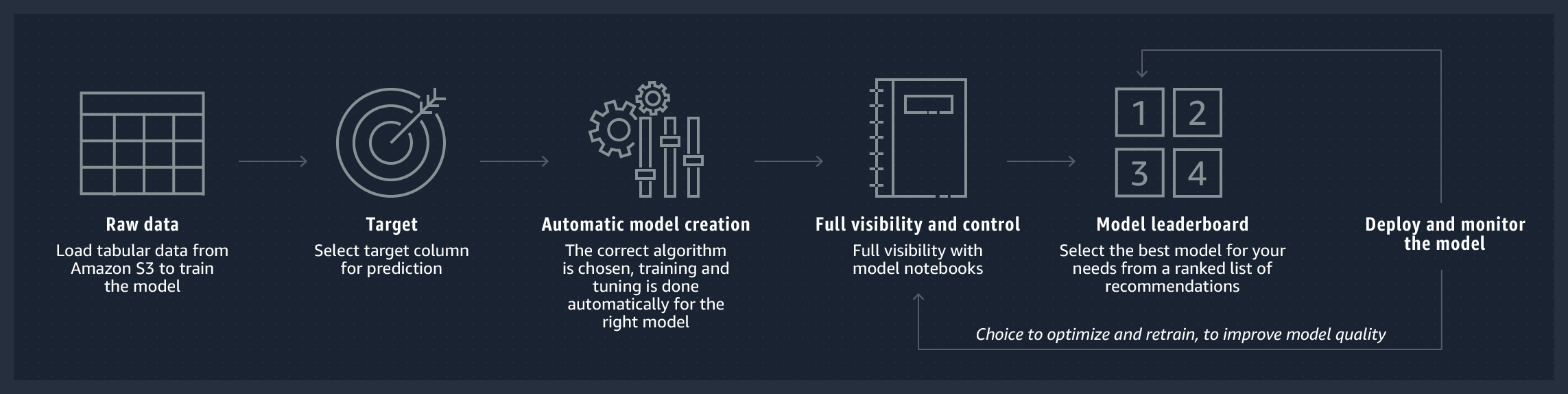
Autopilot
 //https://aws.amazon.com/sagemaker/autopilot/
//https://aws.amazon.com/sagemaker/autopilot/
Amazon SageMaker Autopilot automatically builds, trains, and tunes the best machine learning models based on your data while allowing you to maintain full control and visibility. An example is the use of Amazon SageMaker Autopilot to tackle regression and classification tasks on large datasets up to 100 GB.
Amazon SageMaker Experiments
Amazon SageMaker Experiment is a capability of Amazon SageMaker that lets you organize, track, compare, and evaluate your machine learning experiments.
Model Tracking
Amazon SageMaker ML Lineage Tracking
Amazon SageMaker ML Lineage Tracking creates and stores information about the steps of a machine learning (ML) workflow from data preparation to model deployment. An example of how model lineage is usaged.
SageMaker Debugger
Amazon SageMaker Debugger profiles and debugs training jobs to help resolve such problems such as system bottlenecks, overfitting, saturated activation functions, and vanishing gradients, which can compromise model performance and improve your ML model’s compute resource utilization and performance. Building churn prediction with sagemaker debugger.
Model Monitoring
Amazon SageMaker Model Monitor
Amazon SageMaker Model Monitor continuously monitors the quality of Amazon SageMaker machine learning models in production. An example is Detect NLP data drift using custom Amazon SageMaker Model Monitor.
Amazon SageMaker Clarify
Amazon SageMaker Clarify provides machine learning developers with greater visibility into their training data and models so they can identify and limit bias and explain predictions.
Model Registry
SageMaker model registry
Feature of sagemaker model registry
- Catalog models for production.
- Manage model versions.
- Associate metadata, such as training metrics, with a model.
- Manage the approval status of a model.
- Deploy models to production.
- Automate model deployment with CI/CD.
Model Serving
Amazon SageMaker Serverless Inference
Amazon SageMaker Serverless Inference is a purpose-built inference option that makes it easy for you to deploy and scale ML models. Serverless Inference is ideal for workloads which have idle periods between traffic spurts and can tolerate cold starts.
Amazon Elastic Container Registry (Amazon ECR)
Amazon ECR is an AWS managed container image registry service that is secure, scalable, and reliable. For example How ReliaQuest uses Amazon SageMaker to accelerate its AI innovation by 35x.
Amazon Elastic Kubernetes Service (Amazon EKS)
Amazon Elastic Kubernetes Service is a managed service that you can use to run Kubernetes on AWS without needing to install, operate, and maintain your own Kubernetes control plane or nodes. Example is Evolution of Cresta’s machine learning architecture: Migration to AWS and PyTorch.
Model Deployment
SageMaker project
SageMaker Project teams of data scientists and developers can work on machine learning business problems by creating a SageMaker project with a SageMaker-provided MLOps template that automates the model building and deployment pipelines using continuous integrations and continuous delivery (CI/CD). Build Custom SageMaker Project Templates – Best Practices.
Amazon SageMaker Neo
SageMaker Neo helps data scientists and machine learning engineers to train models once and run them anywhere. It is a deep learning performance optimization for multiple frameworks and hardware. How Deloitte is Improving Animal Welfare with AI at the Edge Using AWS Panorama and AWS Neo.
Workflow Manager
Amazon Step Function
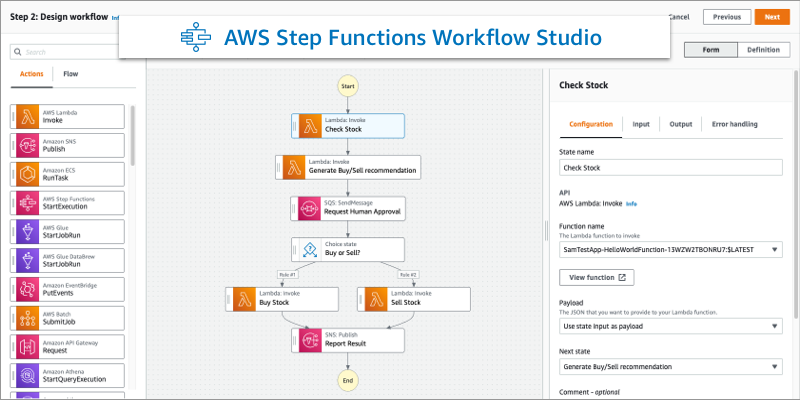
Amazon Step Functions is used for creating and managing workflow. It is an orchestrator for building applications. It is a low-code, visual workflow service developers use to build distributed applications, automate IT and business processes, and build data and machine learning pipelines using AWS services. An example is orchestrating forecasting pipeline using AWS Step Functions.
CI/CD
Amazon CodeCommit
Amazon CodeCommit is a source control service for private git repositories. It is used to privately store and manage assets (such as documents, source code, and binary files) in the cloud. Using CodeCommit for a Continuous Data Journey Towards Developmental Agility and Faster Data Delivery.
Amazon CodeBuild
Amazon CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. Codebuild was used in this blog to optimize budget and time by submitting Amazon Polly voice synthesis tasks in bulk.
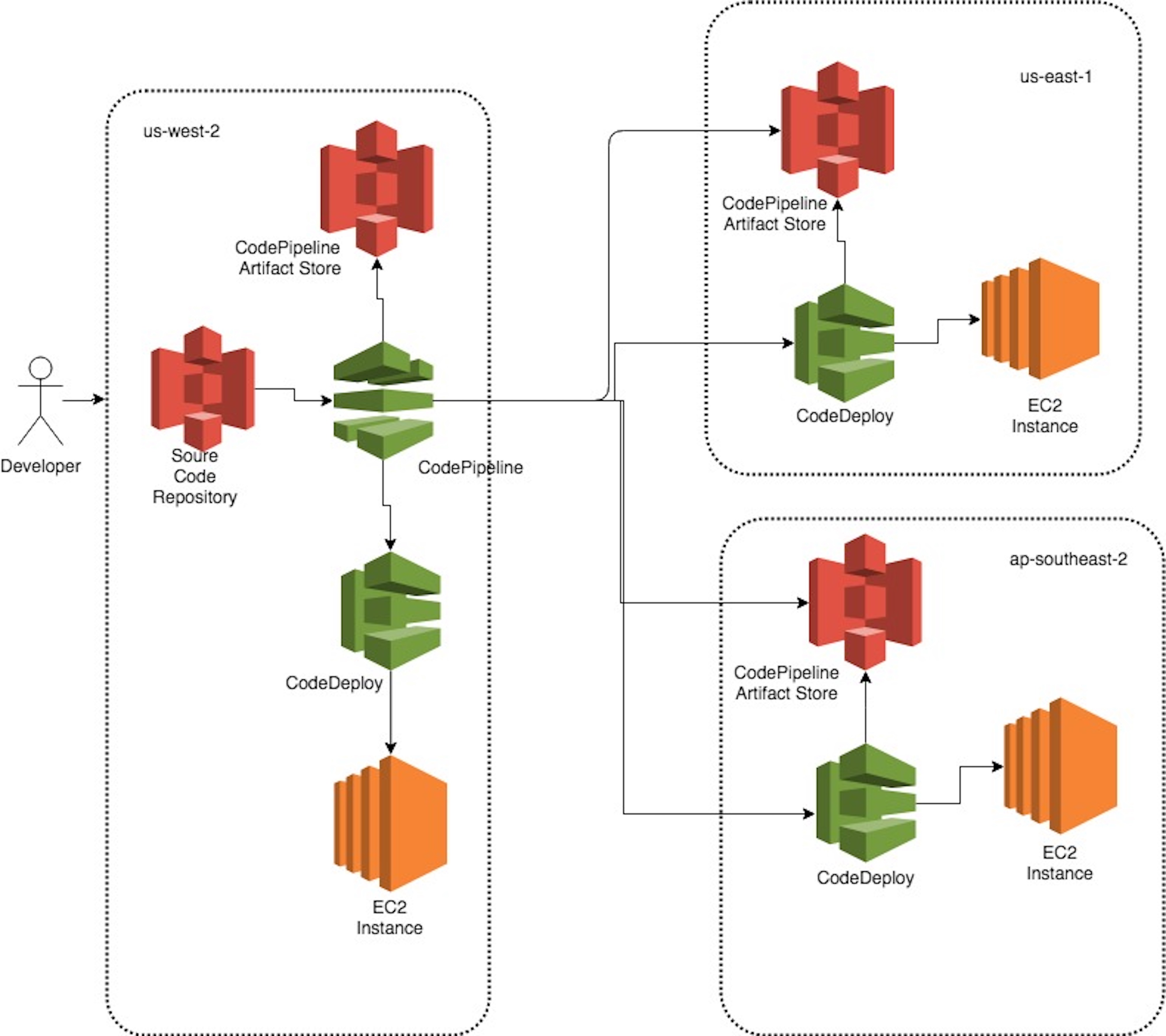
Amazon CodePipeline
Amazon CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. A good use case is using code pipeline to improve your data science workflow with a multi-branch training MLOps pipeline using AWS.
Amazon Code Deploy
CodeDeploy automates application deployments to Amazon EC2 instances, on-premises instances, serverless Lambda functions, or Amazon ECS services. It maximizes application availability.
Amazon CodeGuru Reviewer
Amazon CodeGuru automates code reviews and application profiling. It helps to improve code quality and reduce application performance issues. It helps to identify and estimate expensive lines of code. It uses program analysis and machine learning to improve code.
Amazon CodeArtifact
CodeArtifact is a package manager. Features of CodeArtifact
- securely store packages
- sharing packages during application development
- ingest from third party repositories making it easy for organizations to securely store and share software packages used for application development.Use case using codeartifact for developing serverless application. it makes it easy for organizations to securely store and share software packages used for application development.Use case using codeartifact for developing serverless application.
Conclusion
This article discusses all Amazon Web Services used in different data science life cycle stages. We gave a brief description of each service.

Comments